Criando uma Imagem Personalizada para Treinamento (PyTorch + CPU/GPU)
V1.0 – Setembro 2025
| Versão | Autor | Descrição |
|---|---|---|
| V1.0 – 2025-09-22 | Diogo Hatz 00945205 | Versão Inicial |
Objetivo
Este documento objetiva apresentar os procedimentos necessários para a criação e execução de uma tarefa de treinamento de modelos de IA rodando por meio de uma imagem de container personalizada na Huawei Cloud através do serviço ModelArts. A criação de imagens personalizadas permite uma maior flexibilidade de runtimes e dependências além daquelas já especificadas no serviço.
Especificações
Abaixo segue a lista de versões das runtimes utilizadas neste documento:
- Ubuntu 20.04
- Python 3.13.5
- Miniconda 3
- PyTorch 2.6.0
- PyTorchAudio 2.6.0
- PyTorchVision 0.21.0
OBS
Primeiramente, faz-se necessário criar um bucket no serviço OBS para armazenar o código de treinamento a ser executado e os logs de execução da tarefa. Para isso, navegue até o serviço OBS no console da Huawei Cloud e crie um bucket.
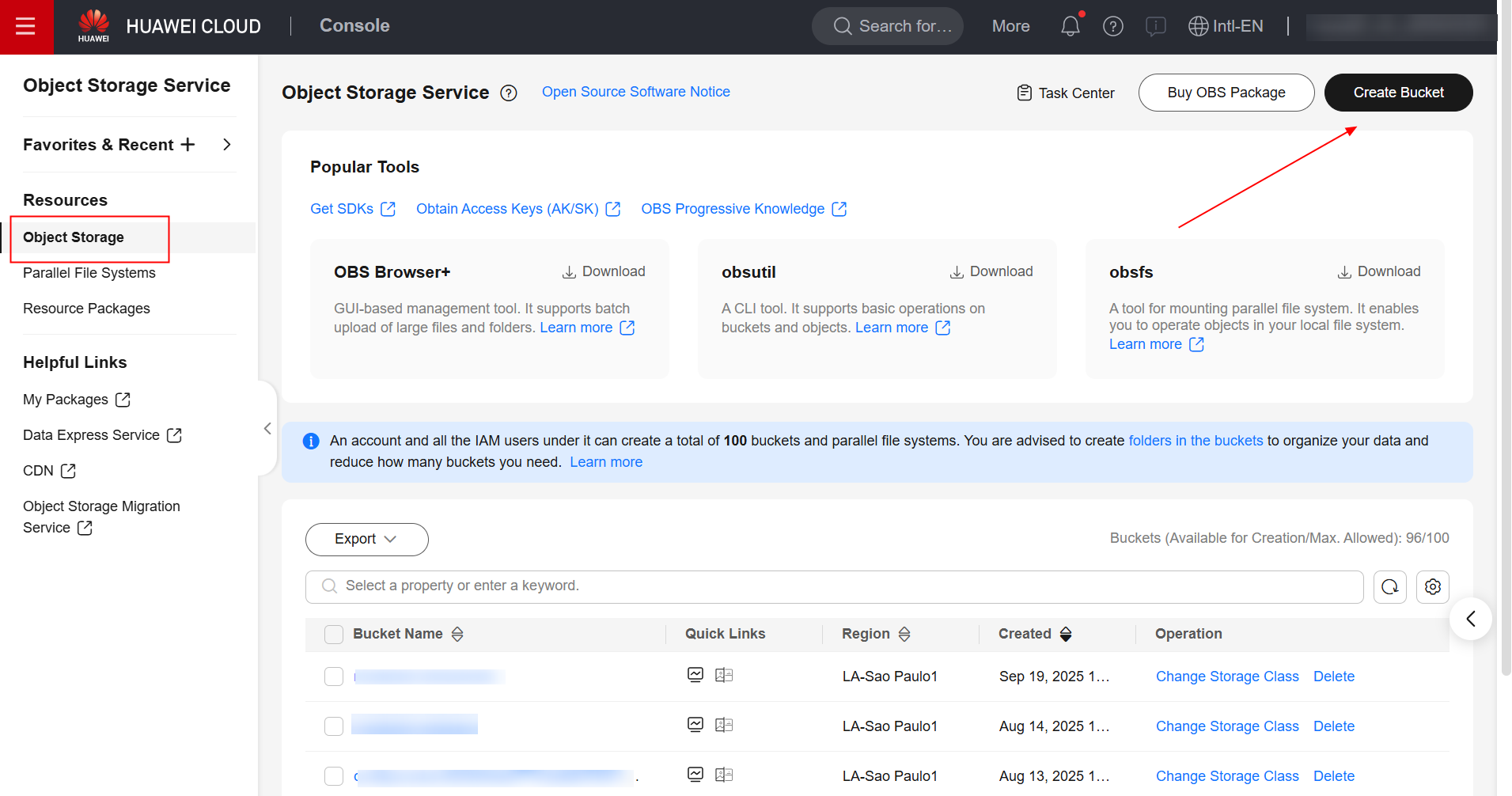
Havendo criado o bucket, crie duas pastas dentro do bucekt, “pytorch” e “logs”. Dentro da pasta “pytorch”, crie mais uma pasta denominada “code”. Segue a estrutura do bucket OBS:
bucket
├── pytorch
├── code
├── teste.py
├── logs
Havendo criado a estrutura do bucket, crie um arquivo Python denominado “teste.py”, cole o seguinte código Python e faça upload na pasta “code” do bucket.
import torch
import torch.nn as nn
import sys
print("Python version:", sys.version)
print("Python version info:", sys.version_info)
x = torch.randn(5, 3)
print(x)
available_dev = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
y = torch.randn(5, 3).to(available_dev)
print(y)
ECS
Havendo preparado o código Python para ser executado pela tarefa de treinamento, navegue agora até o serviço ECS no console da Huawei Cloud e crie uma ECS com o sistema operacional Ubuntu 20.04.
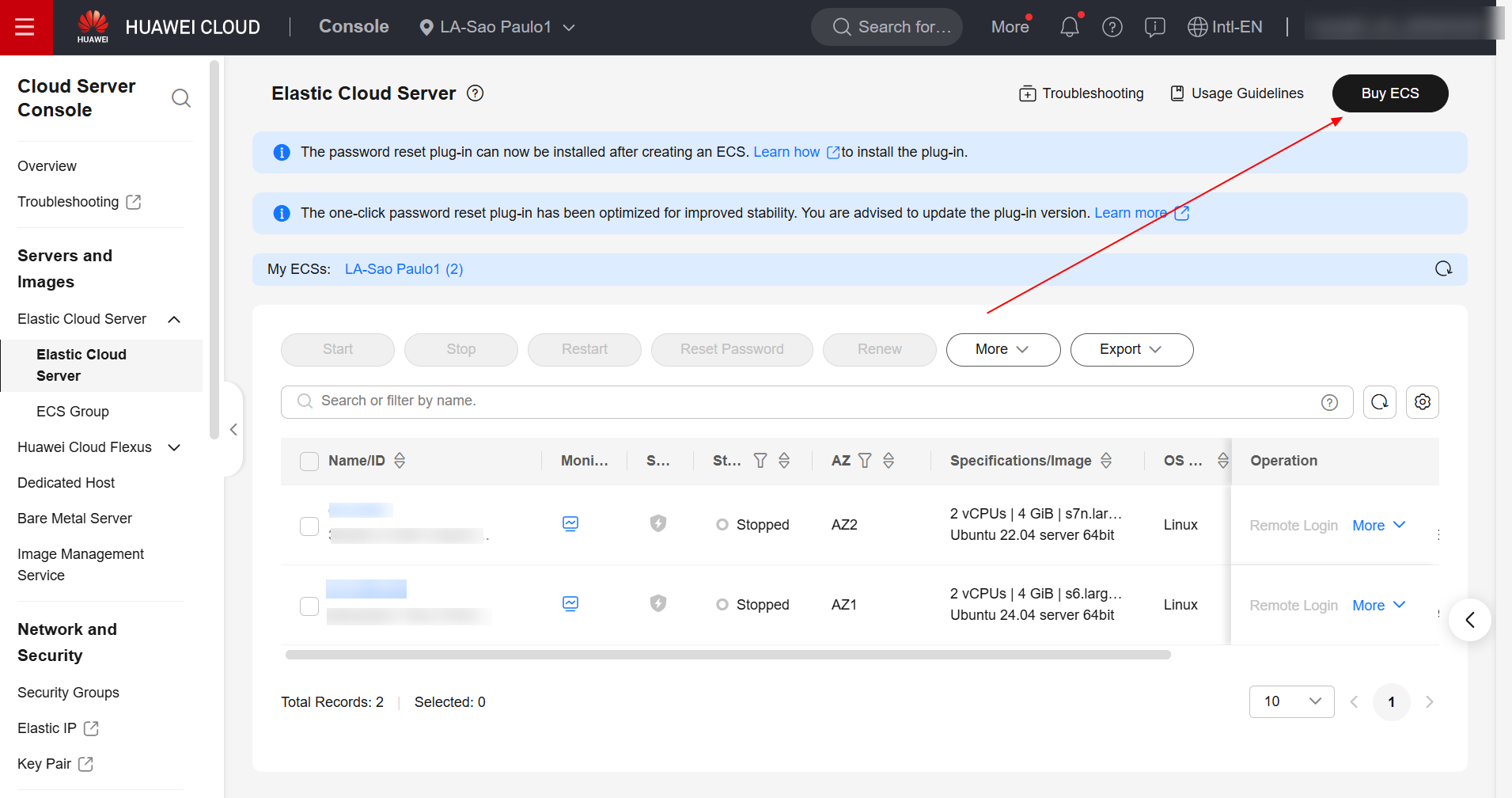
Havendo criado a ECS, faça login na máquina virtual e instale o Docker através do seguinte comando:
sudo apt update && sudo apt-get install docker.io -y
Após a instalação do Docker, crie uma pasta denominada “context” e navegue até essa pasta:
mkdir -p context && cd context
Feito isso, realize o download dos seguintes módulos do PyTorch:
- torch-2.6.0+cu118-cp313-cp313-linux_x86_64.whl
- torchaudio-2.6.0+cpu-cp313-cp313-linux_x86_64.whl
- torchvision-0.21.0+cu118-cp313-cp313-linux_x86_64.whl
wget https://download.pytorch.org/whl/cu118/torch-2.6.0%2Bcu118-cp313-cp313-linux_x86_64.whl#sha256=8d30eb2870ffe05d81ec513bdb08c0f2bab9fd1bd4fbc6e5681fad855c7b99e3
wget https://download.pytorch.org/whl/cpu/torchaudio-2.6.0%2Bcpu-cp313-cp313-linux_x86_64.whl#sha256=6fae44f4d5b401a048f997d2fedf43566634b45e44950224b2b99ea1db18c68a
wget https://download.pytorch.org/whl/cu118/torchvision-0.21.0%2Bcu118-cp313-cp313-linux_x86_64.whl#sha256=2e85300054af1feda7213f578039097ec816683a7ef0b6e199be17f70e220a53
Faça também o download do Minoconda3:
- Miniconda3-py313_25.7.0-2-Linux-x86_64.sh
wget https://repo.anaconda.com/miniconda/Miniconda3-py313_25.7.0-2-Linux-x86_64.sh
Feito isso, a estrutura da pasta “context” deve estar da seguinte forma:
context
├── Miniconda3-py313_25.7.0-2-Linux-x86_64.sh
├── torch-2.6.0+cu118-cp313-cp313-linux_x86_64.whl
├── torchaudio-2.6.0+cpu-cp313-cp313-linux_x86_64.whl
└── torchvision-0.21.0+cu118-cp313-cp313-linux_x86_64.whl
Crie um arquivo denominado “Dockerfile” e então cole o seguinte conteúdo:
# The host must be connected to the public network for creating a container image.
# Base container image at https://github.com/NVIDIA/nvidia-docker/wiki/CUDA
#
# https://docs.docker.com/develop/develop-images/multistage-build/#use-multi-stage-builds
# require Docker Engine >= 17.05
#
# builder stage
FROM nvidia/cuda:13.0.1-cudnn-runtime-ubuntu22.04 AS builder
# The default user of the base container image is root.
# USER root
# Python 3.13
ENV DEBIAN_FRONTEND=noninteractive
ENV TZ=America/New_York
RUN apt update && apt install software-properties-common -y && add-apt-repository ppa:deadsnakes/ppa && apt update && apt install python3.13 -y
# Copy the installation files to the /tmp directory in the base container image.
COPY Miniconda3-py313_25.7.0-2-Linux-x86_64.sh /tmp
COPY torch-2.6.0+cu118-cp313-cp313-linux_x86_64.whl /tmp
COPY torchvision-0.21.0+cu118-cp313-cp313-linux_x86_64.whl /tmp
COPY torchaudio-2.6.0+cpu-cp313-cp313-linux_x86_64.whl /tmp
# https://conda.io/projects/conda/en/latest/user-guide/install/linux.html#installing-on-linux
# Install Miniconda3 to the /home/ma-user/miniconda3 directory of the base container image.
RUN bash /tmp/Miniconda3-py313_25.7.0-2-Linux-x86_64.sh -b -p /home/ma-user/miniconda3
# Install torch*.whl using the default Miniconda3 Python environment in /home/ma-user/miniconda3/bin/pip.
RUN cd /tmp && \
/home/ma-user/miniconda3/bin/pip install --no-cache-dir \
/tmp/torch-2.6.0+cu118-cp313-cp313-linux_x86_64.whl \
/tmp/torchvision-0.21.0+cu118-cp313-cp313-linux_x86_64.whl \
/tmp/torchaudio-2.6.0+cpu-cp313-cp313-linux_x86_64.whl
# Create the final container image.
FROM nvidia/cuda:13.0.1-cudnn-runtime-ubuntu22.04
# Install vim and cURL in the open-source image site.
RUN apt-get update && \
apt-get install -y vim curl && \
apt-get clean
# Add user ma-user (UID = 1000, GID = 100).
# A user group whose GID is 100 of the base container image exists. User ma-user can directly use it.
RUN useradd -m -d /home/ma-user -s /bin/bash -g 100 -u 1000 ma-user
# Copy the /home/ma-user/miniconda3 directory from the builder stage to the directory with the same name in the current container image.
COPY --chown=ma-user:100 --from=builder /home/ma-user/miniconda3 /home/ma-user/miniconda3
# Configure the preset environment variables of the container image.
# Set PYTHONUNBUFFERED to 1 to avoid log loss.
ENV PATH=$PATH:/home/ma-user/miniconda3/bin \
PYTHONUNBUFFERED=1
# Set the default user and working directory of the container image.
USER ma-user
WORKDIR /home/ma-user
Verifique que o conteúdo da pasta “context” será a seguinte:
context
├── Dockerfile
├── Miniconda3-py313_25.7.0-2-Linux-x86_64.sh
├── torch-2.6.0+cu118-cp313-cp313-linux_x86_64.whl
├── torchaudio-2.6.0+cpu-cp313-cp313-linux_x86_64.whl
└── torchvision-0.21.0+cu118-cp313-cp313-linux_x86_64.whl
Feito isso, realize o build da imagem através do seguinte comando:
docker build . -t model-arts:1.0
SWR
Havendo realizado o build da imagem, agora navegue até o serviço SWR no console da Huawei Cloud e crie uma organização.
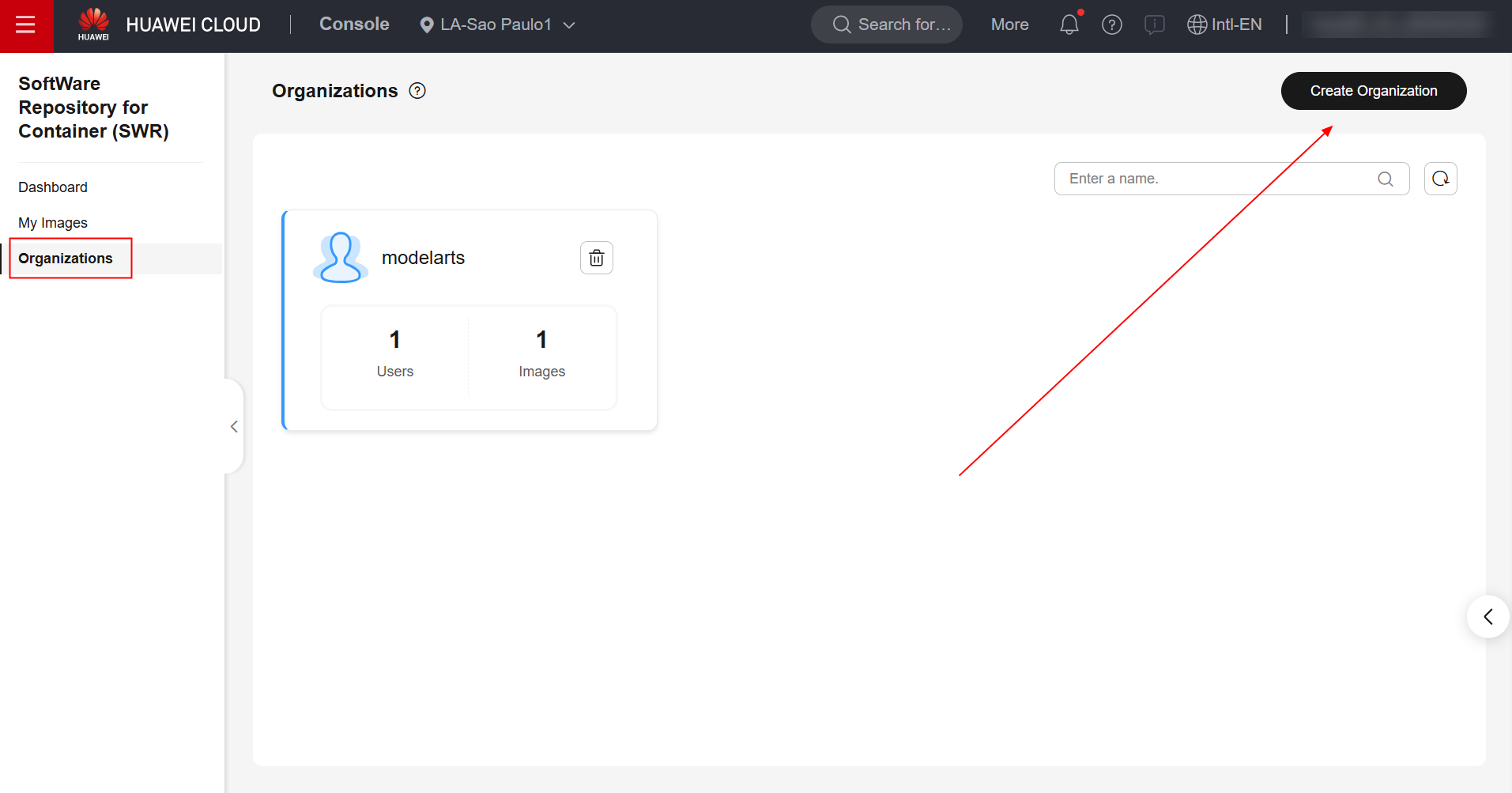
Após a criação da organização, navegue até a seção “My Images”, no painel da esquerda, e clique em “Upload Through Client”. Feito isso, clique em “Generate Login Command”, copie o comando de login gerado e cole na ECS.
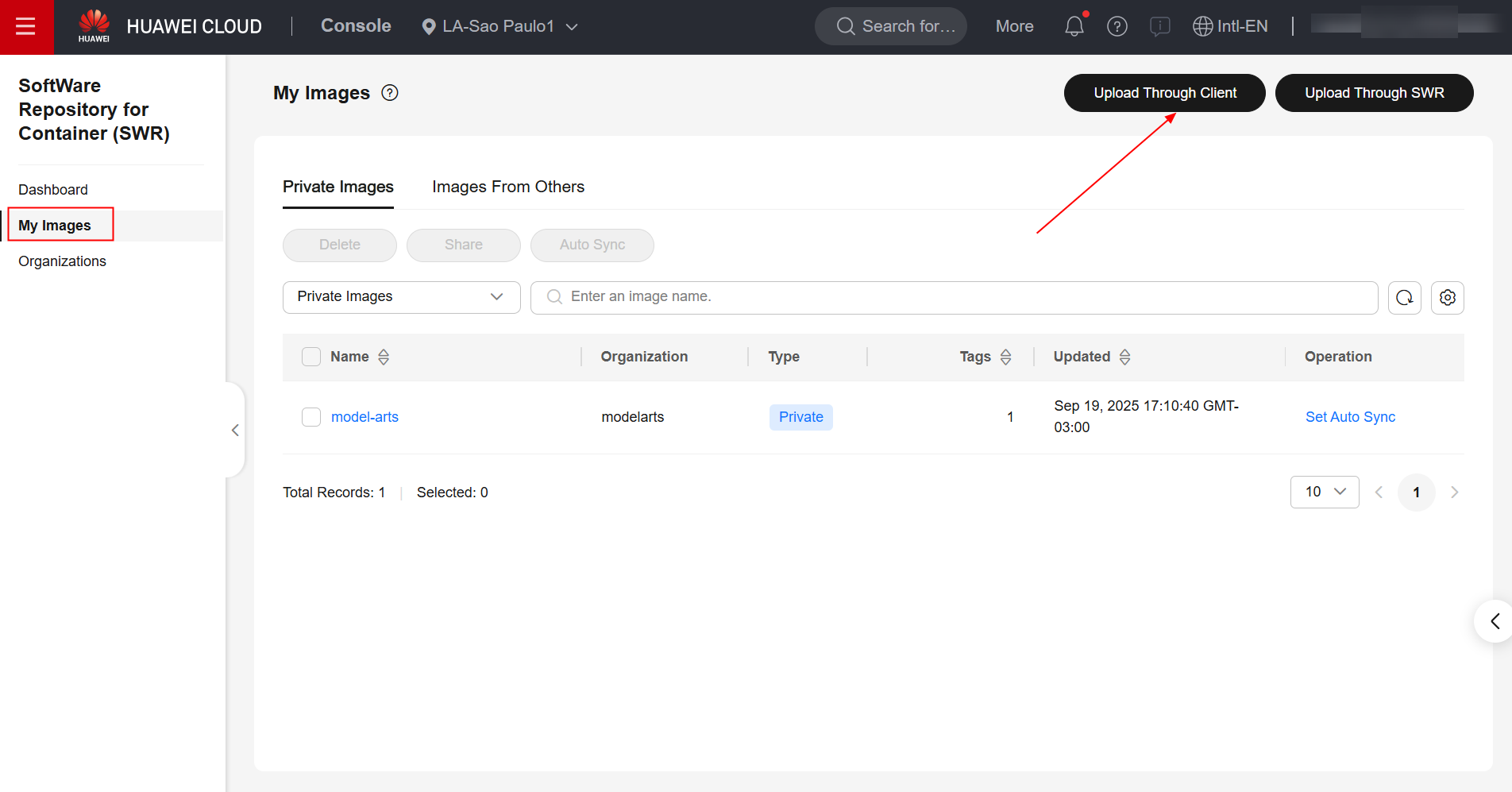
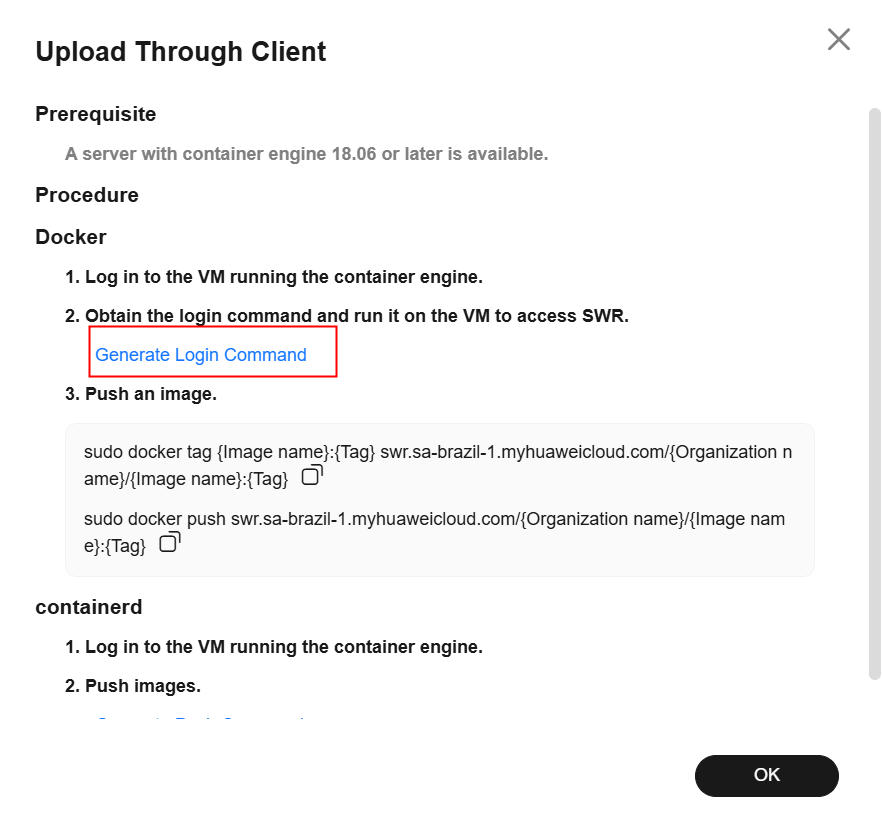
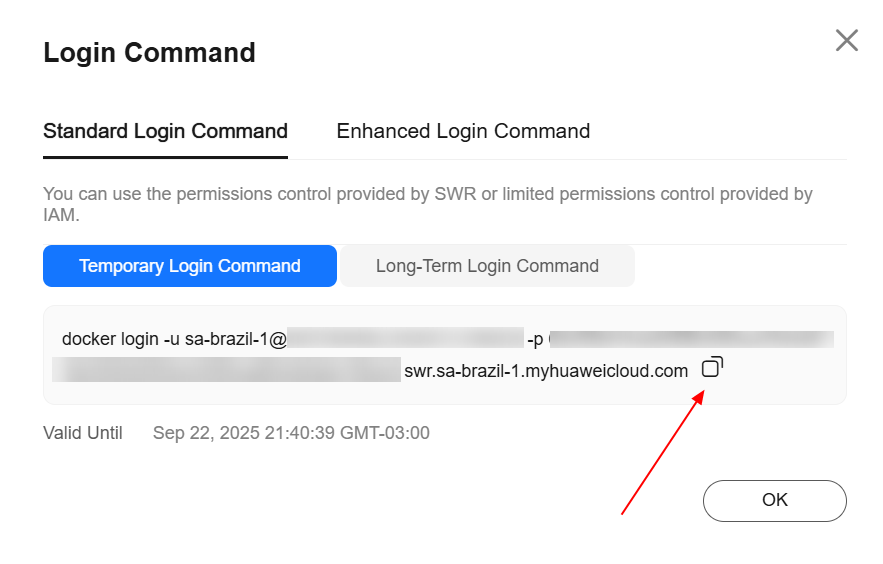

Digite o seguinte comando para atribuir uma tag à imagem, substituindo as informações de região, domínio e organização pelos valores reais:
sudo docker tag model-arts:1.0 swr.{region-id}.{domain}/{organization-name}/model-arts:1.0
Digite o seguinte comando para realizar o upload da imagem para o repositório SWR, substituindo as informações de região, domínio e organização pelos valores reais:
sudo docker push swr.{region-id}.{domain}/{organization-name}/model-arts:1.0
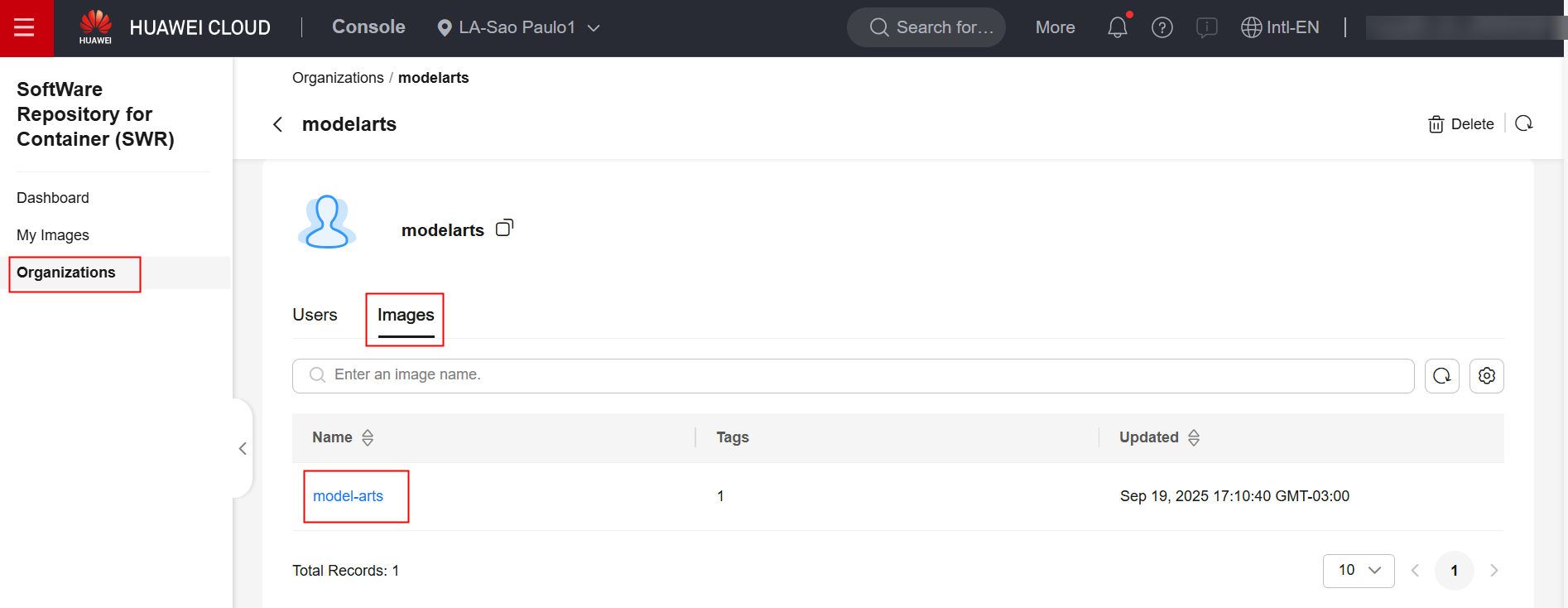
Verifique no console do SWR que a imagem foi transferida com sucesso para o repositório do SWR:
ModelArts
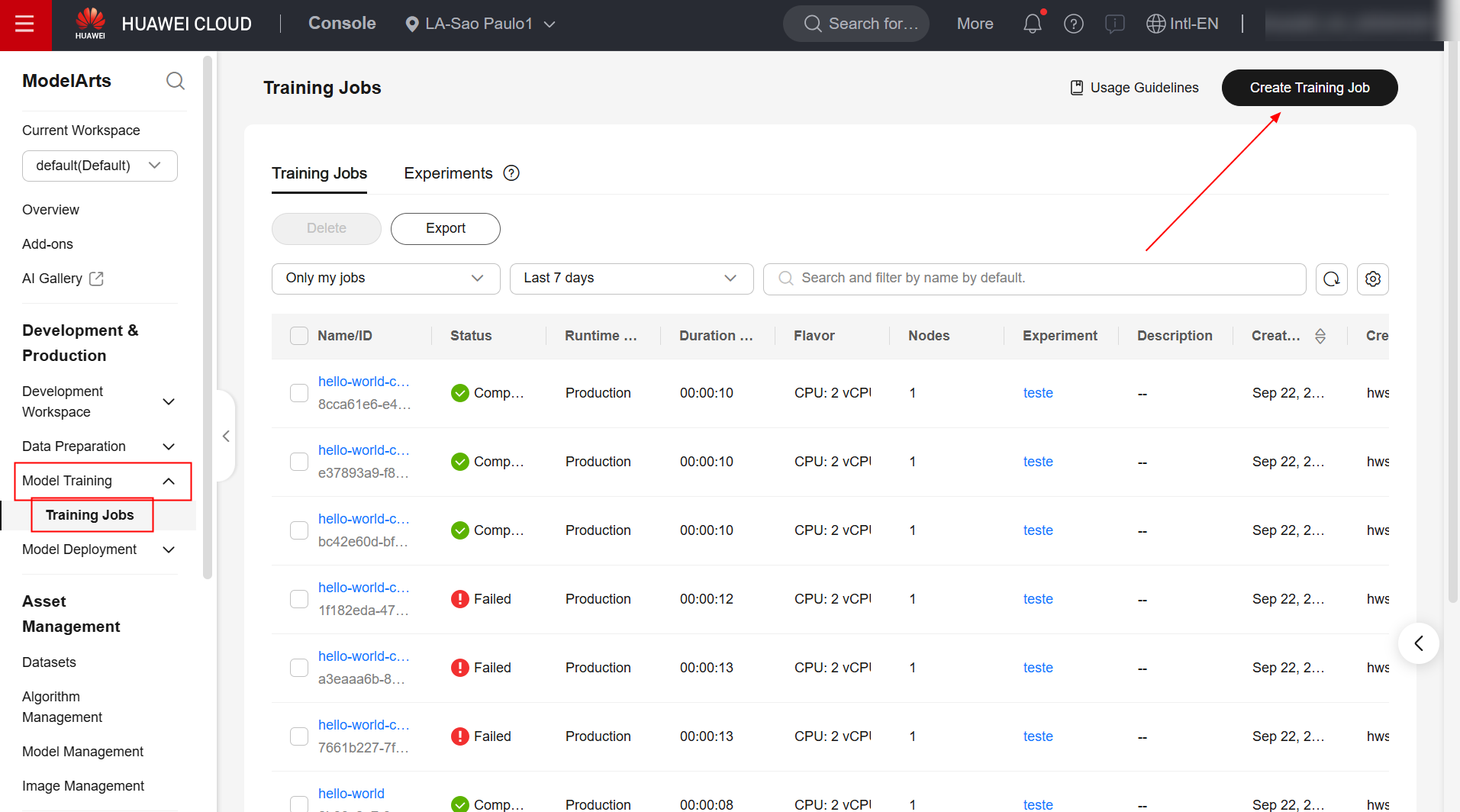
Para criar uma tarefa de treinamento de modelos no serviço ModelArts, primeiramente navegue até a página do produto no console da Huawei Cloud e clique em “Create Training Job”.
Preencha os campos “Algorithm Type”, “Boot Mode”, “Image”, “Boot Command” e “Job Log Path” como especificado abaixo. Para as demais configurações, retenha o padrão.
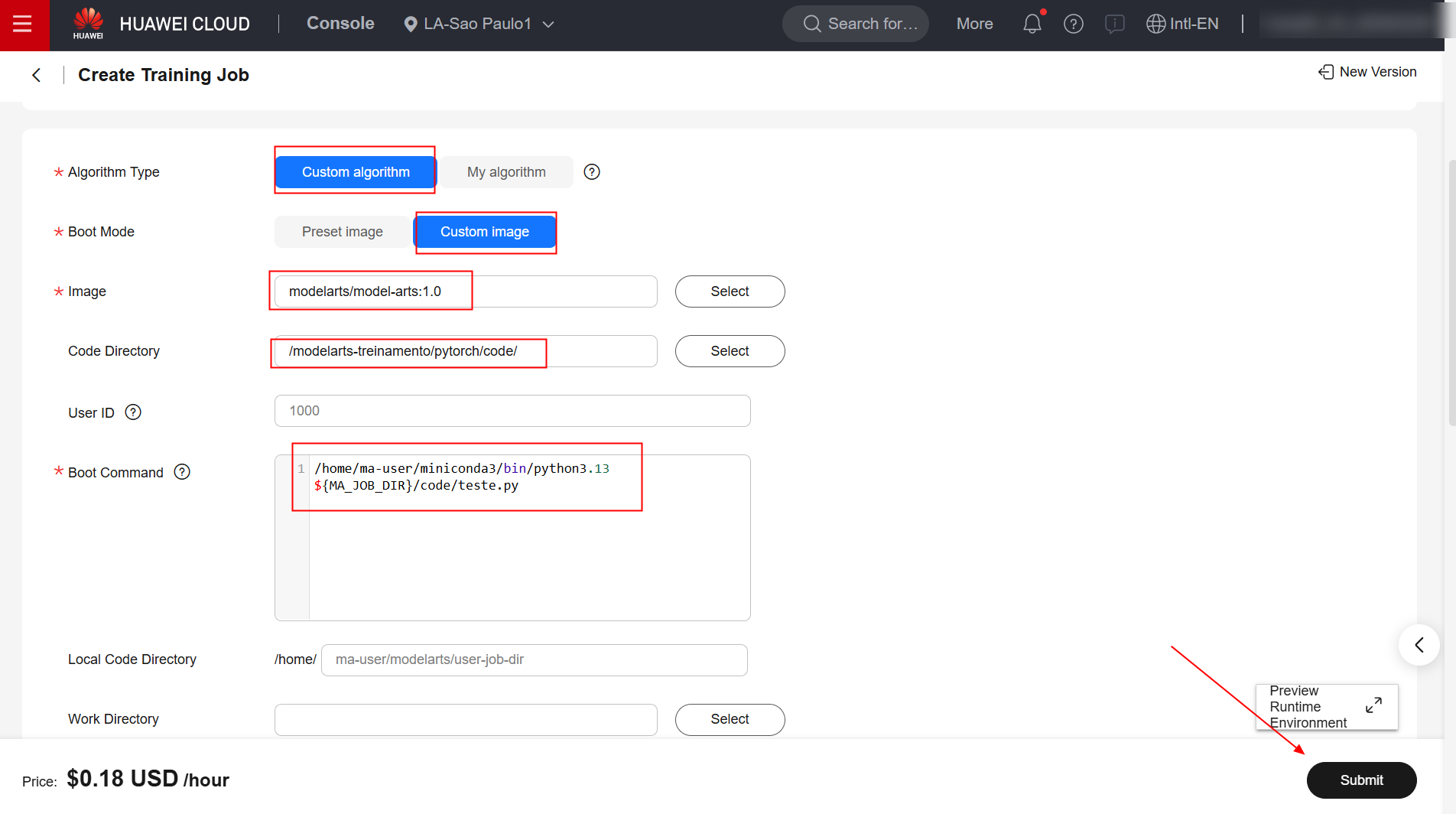
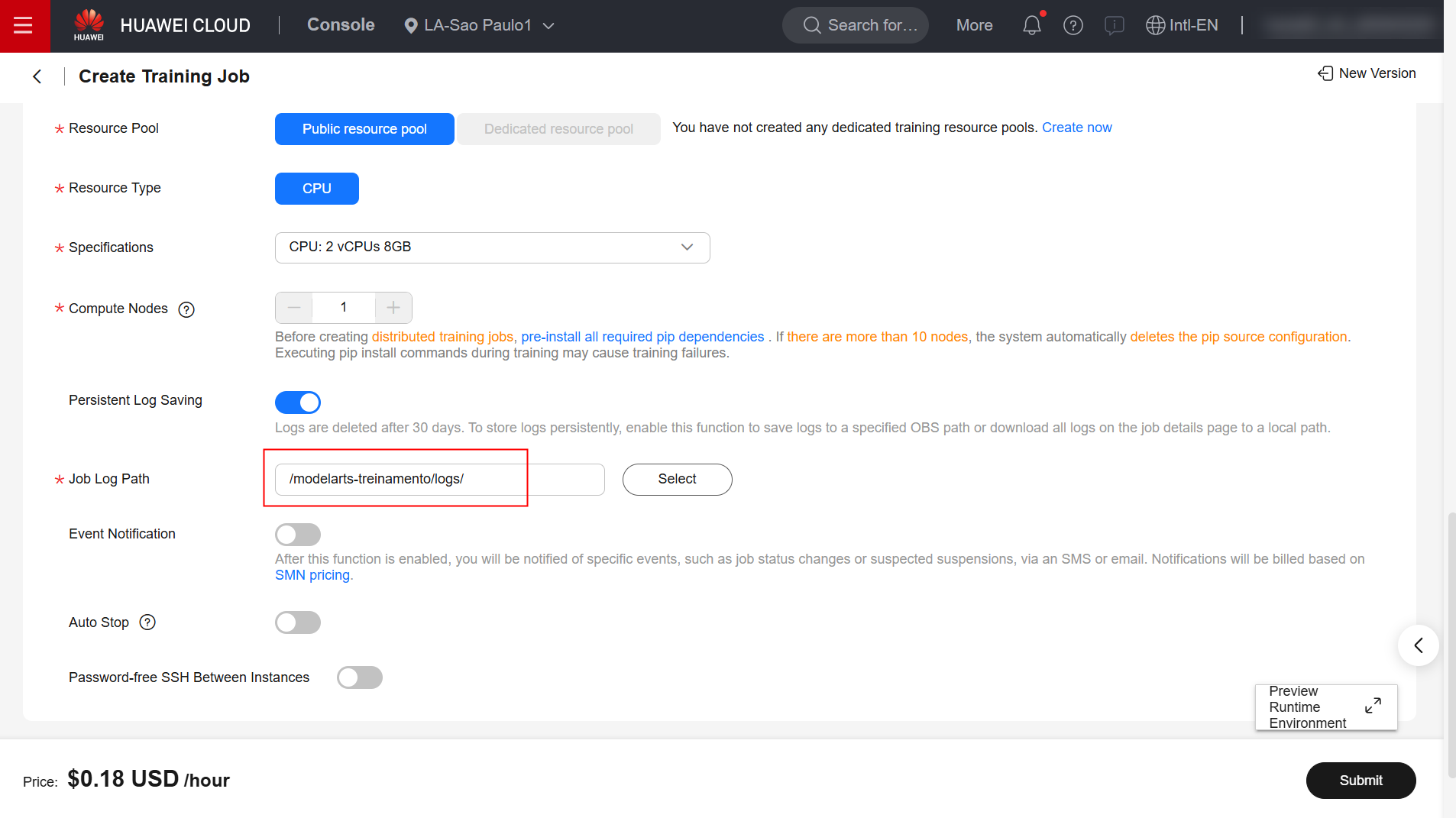
/home/ma-user/miniconda3/bin/python3.13 ${MA_JOB_DIR}/code/teste.py
Feito isso, confirme a criação da tarefa e aguarde até a sua finalização.
Exemplo
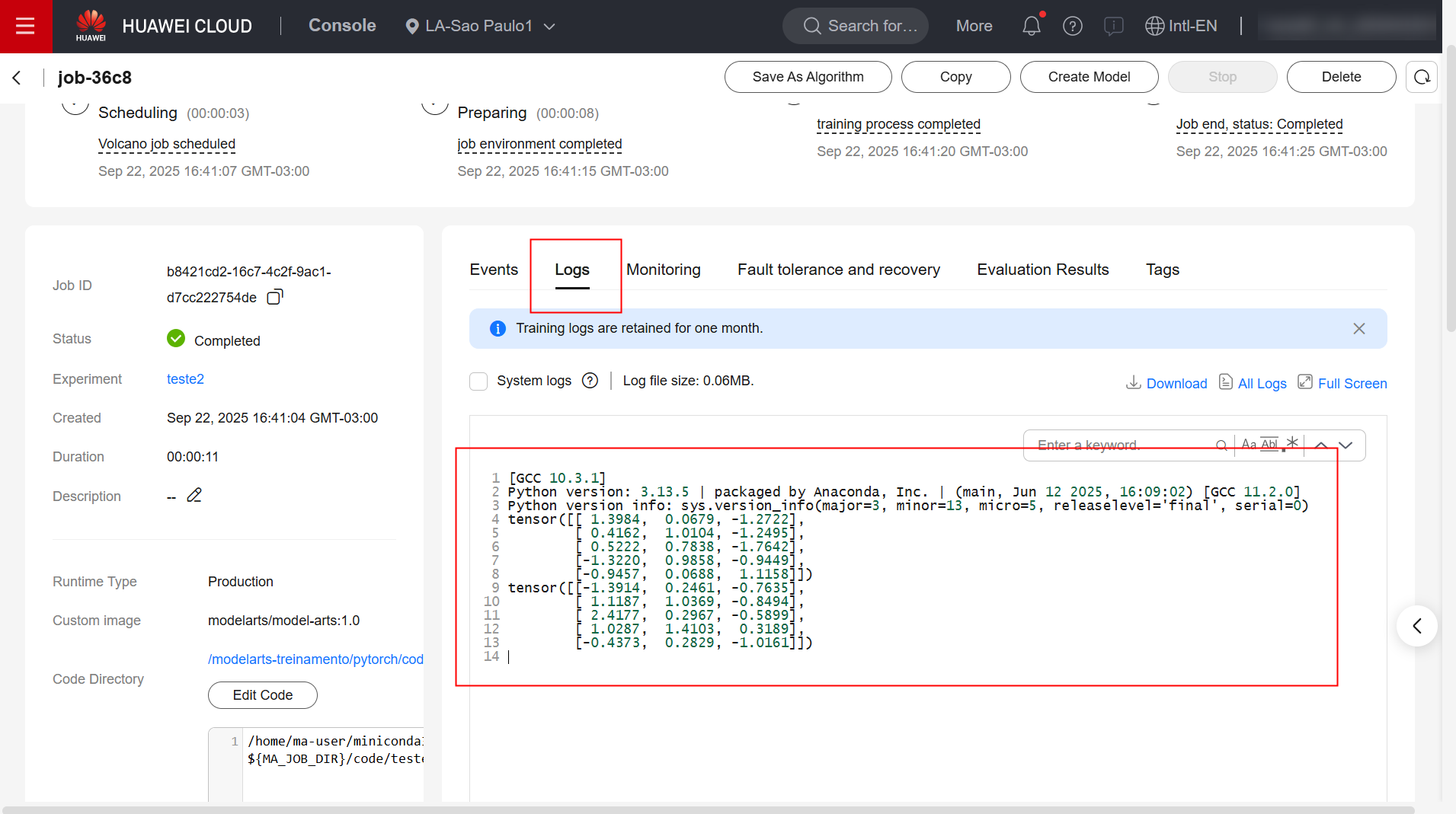
Verifique os logs de execução da tarefa de treinamento:
Referências
-
Documentação do ModelArts: https://support.huaweicloud.com/intl/en-us/docker-modelarts/develop-modelarts-0097.html
-
Documentação do ModelArts: https://support.huaweicloud.com/intl/en-us/develop-modelarts/develop-modelarts-0011.html